SwiftEdit: Lightning Fast Text-guided Image Editing via One-step Diffusion
✨ Accepted at CVPR 2025, Nashville ✨
Trong-Tung Nguyen
Quang Nguyen
Khoi Nguyen
Anh Tran
Cuong Pham
Qualcomm AI Research
Make your edit in just 0.23 seconds !!!
Paper
Supplemental Material
Code (Official)
BibTex
🤗 HuggingFace Paper
Abstract
Recent advances in text-guided image editing enable users to perform image edits through simple text inputs,
leveraging the extensive priors of multi-step diffusion-based text-to-image models. However,
these methods often fall short of the speed demands required for real-world and on-device applications due to
the costly multi-step inversion and sampling process involved. In response to this, we introduce SwiftEdit,
a simple yet highly efficient editing tool that achieve instant text-guided image editing (in 0.23s).
The advancement of SwiftEdit lies in its two novel contributions: a one-step inversion framework that enables one-step image
reconstruction via inversion and a mask-guided editing technique with our proposed attention rescaling mechanism to
perform localized image editing. Extensive experiments are provided to demonstrate the effectiveness and efficiency of SwiftEdit.
In particular, SwiftEdit enables instant text-guided image editing, which is extremely faster than previous multi-step methods
(at least 50 times faster) while maintain a competitive performance in editing results.
Video Demonstration
SwiftEdit is a user-friendly, lightning-fast editing tool that enables instant edits through simple and flexible prompts,
delivering highly desirable results. Watch the video to learn more!
Approach
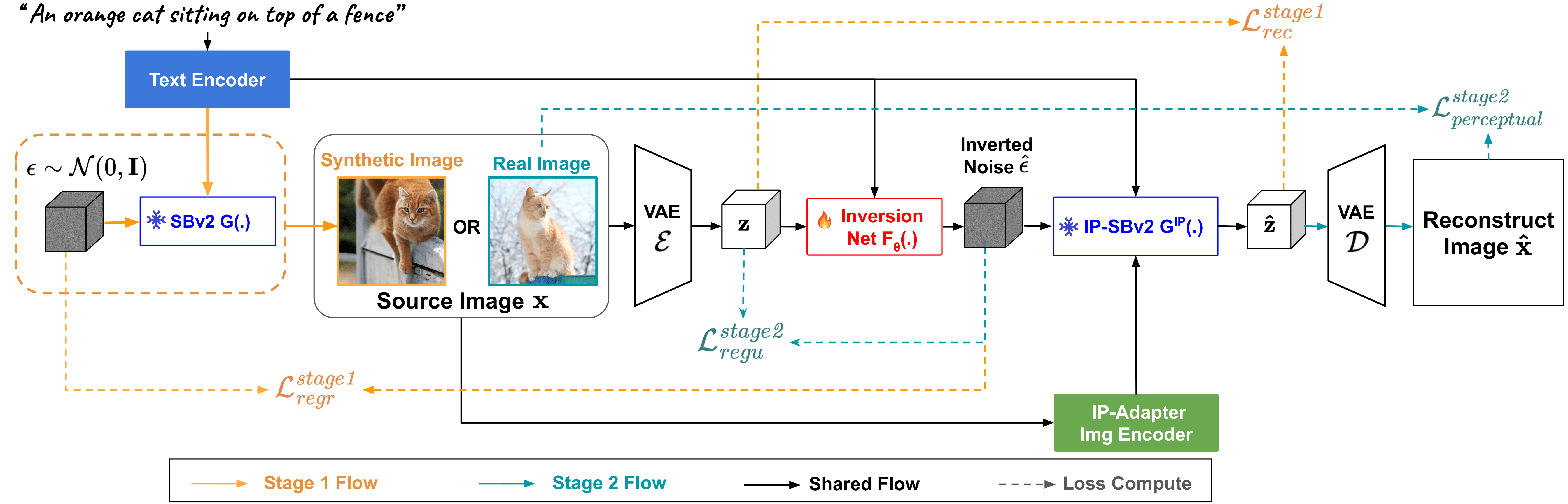
We introduce a two-stage training strategy to train a one-step inversion network that predicts the inverted noise to reconstruct a given source input image when passed through SBv2. This enables single-step reconstruction of any input images without further retraining.
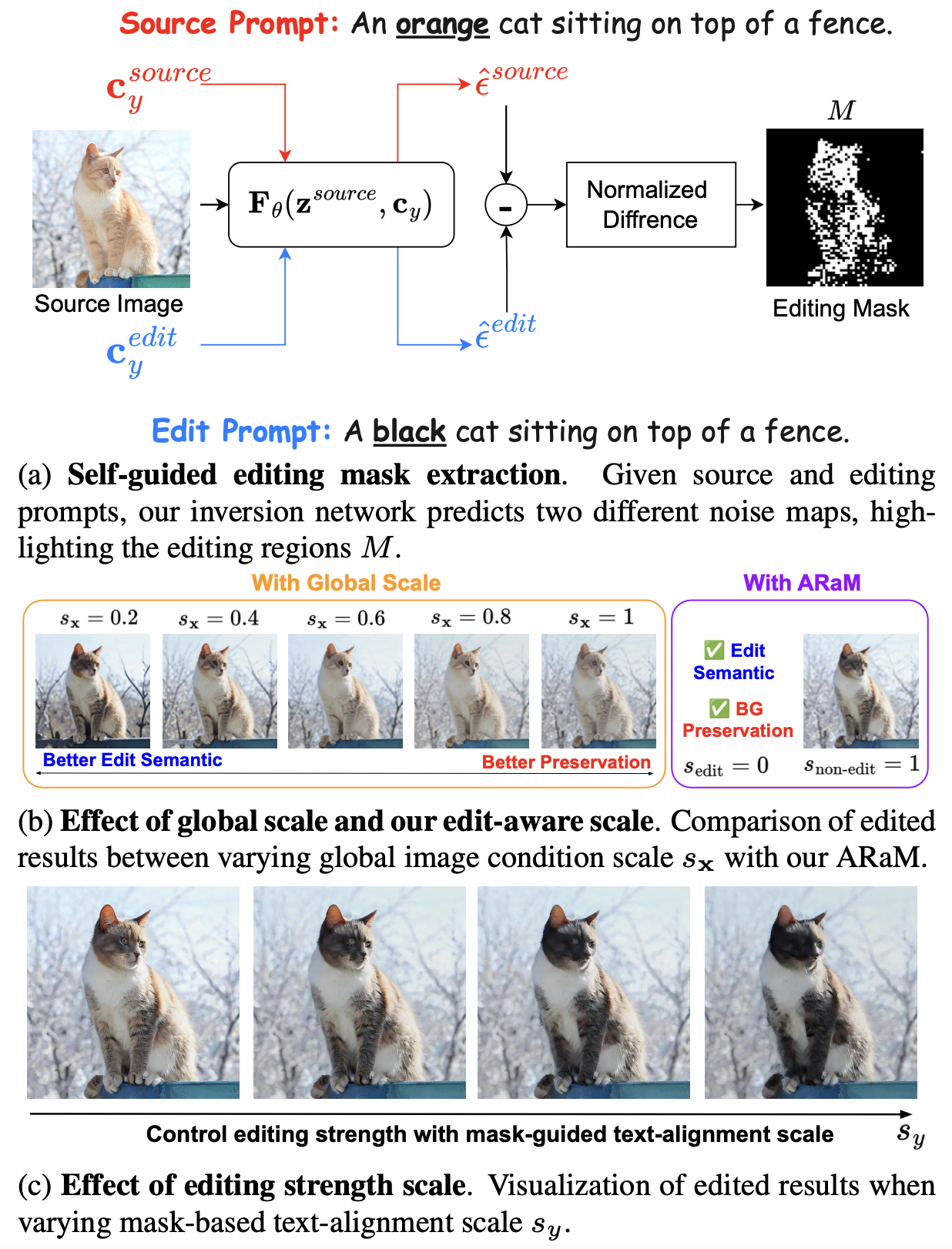
Post training, we develop a self-guided editing mask, which is automatically extracted from our well-trained one-step inversion network to locate edited regions. Based on this mask, we proposed an attention-rescaling technique to perform disentangled editing and control the editing strength while preserving essential background elements.
Acknowledgements:
We give special thanks to Thuan Hoang Nguyen for his early discussion on this research topic and his wonderful work SwiftBrush. We thank
Imagic and DreamBooth for their awesome webpage and HuggingFace team for their wonderful diffusers framework.